前言
本文简单记录一下个人在研究stable diffusion中的过程中对扩散模型(diffusion model)的工作原理和模型结构的学习。
正文
一、Stable Diffusion模型构成
stable diffusion由三个部分组成:文本特征提取模型、图像特征编解码模型、噪声预测模型。
里面用到的最基础神经网络结构包括Transformer和ResNet。
-
文本特征提取模型
Text Encoder是一个基于Transformer的语言模型,比如ClipText、BERT等,对输入的文本prompts生成token embeddings,作用就是理解输入的提示文本信息,并得到高维特征,指导后续的噪声预测模型的预测方向。
-
图像特征编解码模型
这里的编解码由Image Encoder和Image Decoder组成,分别用在训练和推理阶段中,在训练阶段,会使用Image Encoder和Text Encoder配对训练,用于匹配输入的文本提示和输出的生成图像。在推理阶段使用Image Encoder的逆过程从经过文本指导的噪声预测器那里解码恢复,生成最终图像。
-
噪声预测模型
这是本文的主角:扩散模型。噪声预测,顾名思义,不是用来预测图像的,而是预测噪声,这是stable diffusion的核心组件,还是Dall-E 2和Imagen的主要部分,几乎现在的大型图像生成模型都用到了扩散结构。
二、Diffusion Model
1、工作原理
扩散的意思是迭代预测前一步中可能添加的噪声,将预测的噪声从输入中减去,再进行下一步预测,这样一步步的扩散,最终得到去掉所有可能噪声后的图像。
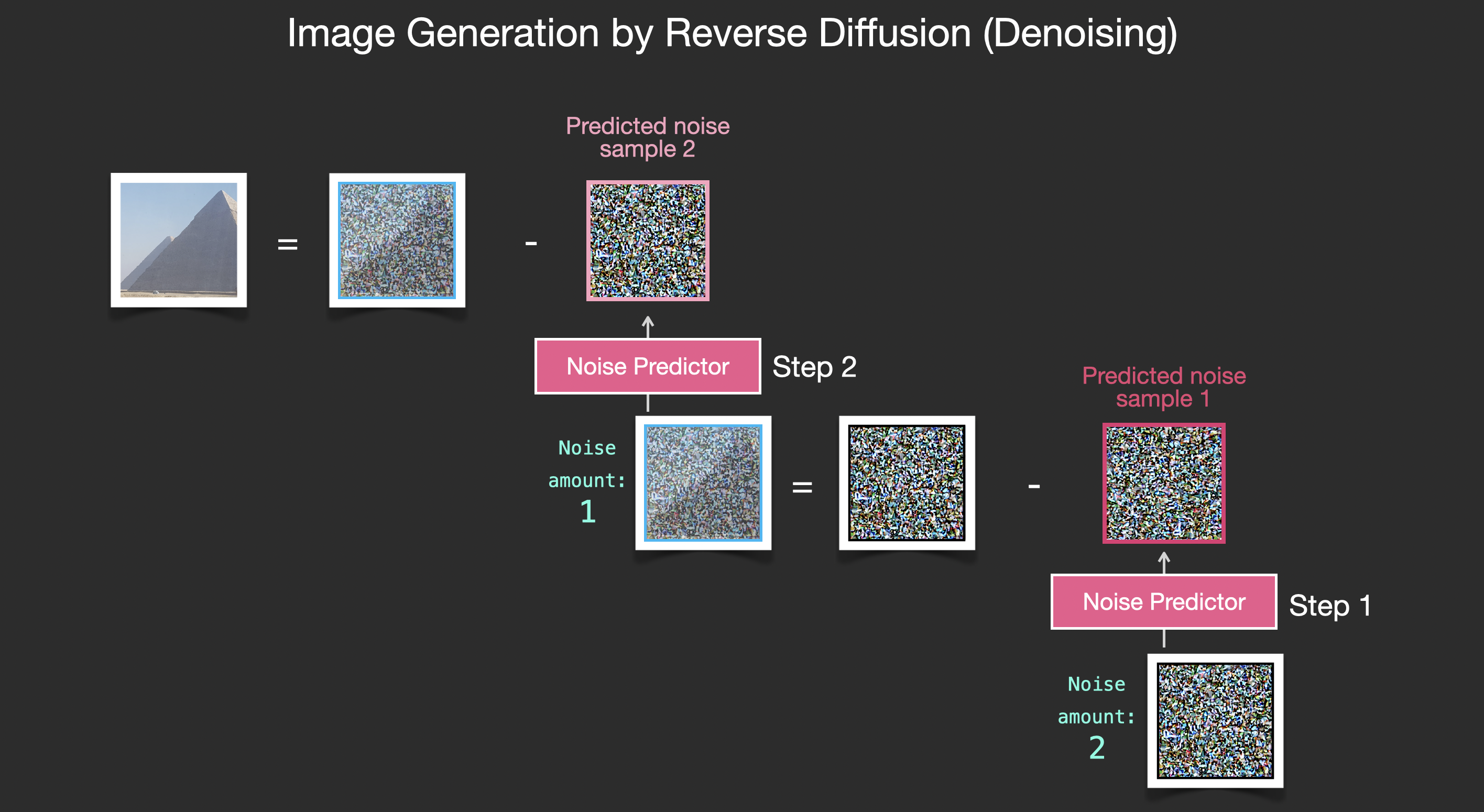 |
|---|
| via 噪声预测过程 |
以上是从推理过程角度看扩散模型是怎么“扩散”的,在训练过程中是相反的过程:每一步中都会在前一步基础上添加一份噪声,这样既得到了Label也得到了Output,同时完成训练和损失计算。
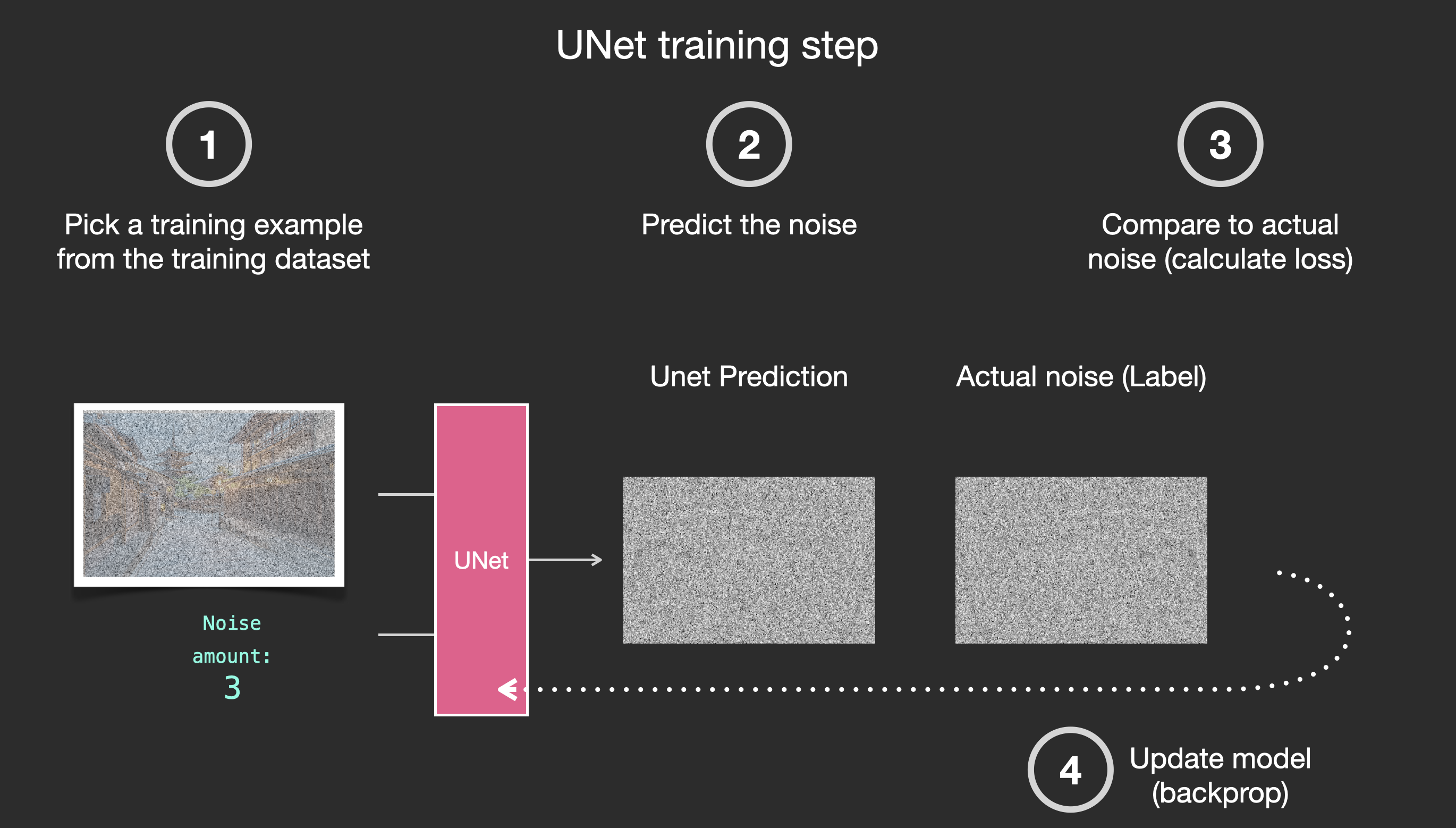 |
|---|
| via 训练过程 |
2、模型构造
整体框架是基于UNet,内部使用ResNet和Transformer,Attention主要用于文本特征嵌入,基于文本的扩散结构在下一节中介绍了,这里只分析最根本的图像扩散结构。
| via 潜空间特征与显式视觉空间对应关系 |
扩散模型是在潜空间上对高维特征的处理,不直接处理显式图像,这样可以保证推理效率。
扩散模型基于多个扩散结构的迭代,每步的结构相同,对应图像降噪生成的不同阶段,可以将这些不同阶段得到的潜空间特征解码出显式图像,能观察到一幅图像是如何神奇的一步步被生成出来的。
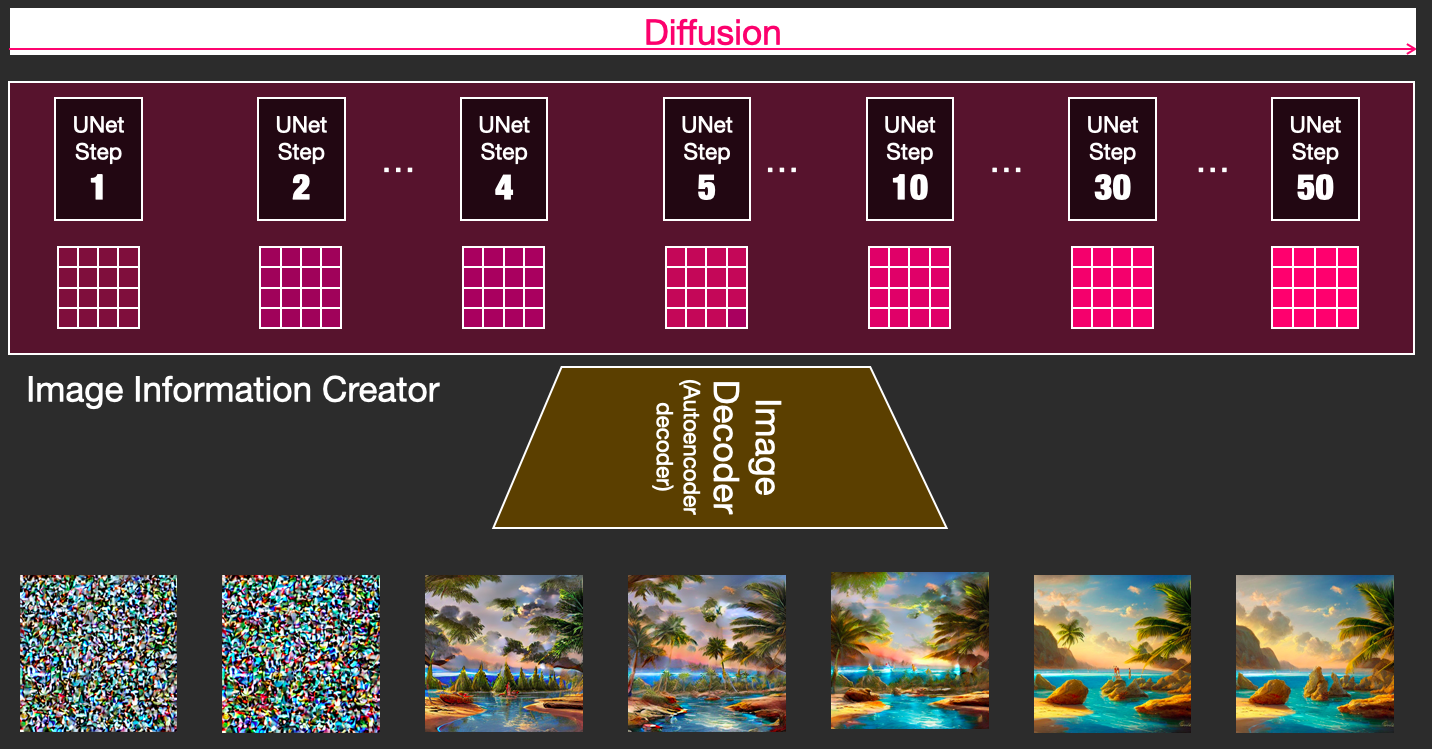 |
|---|
| via 可视化不同降噪阶段 |
三、Diffusioon Model with Text
扩散的原理已经介绍了,就是迭代预测前一步中可能添加的噪声,并减去预测噪声,最终恢复图像的过程。在没有文本提示的情况下,输入只有随机噪声图像,这样生成的图像其实是没有意义的,一定要有指导性的特征信息才能生成特定的图像,所以需要将文本提示信息嵌入到扩散结构中。
文本提示信息经过文本特征提取模型已经转换成文本特征向量了,只需要在扩散模型的每一步之后加入注意力模块将文本特征嵌入潜空间特征中。
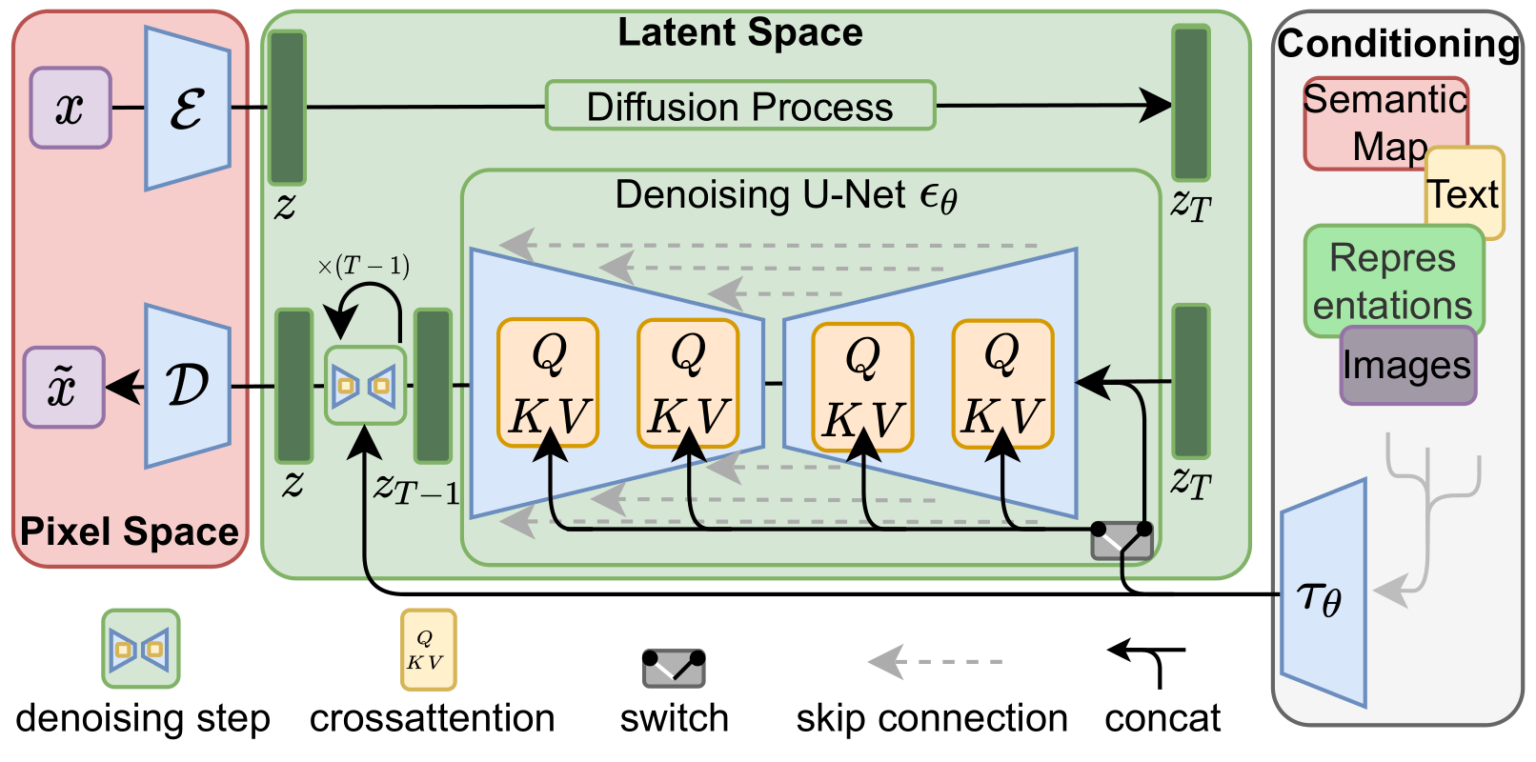 |
|---|
| via 带文本提示的扩散过程 |
四、Diffusion VS GAN
图像生成是当前 AIGC 领域最热门的方向之一。扩散模型开创了图像生成的新时代,实现了前所未有的图像质量和模型灵活性水平,被应用在DALLE 2、Imagen和Stable Diffusion中。
扩散模型基于迭代运算,可以在迭代中对简单目标进行优化,实现最终目标,但是对算力要求很高(想一想,DALLE 2、Imagen和Stable Diffusion这些模型,哪个不是巨无霸体型![]() )。
)。
这些模型先不说能不能复现,一般的中小公司连设备都不够!最终只能使用API的方式依赖头部公司,头部公司进一步垄断市场。
在扩散模型之前,生成对抗网络(GAN)是图像生成模型中常用的基础架构。相比于扩散模型,GAN 没有迭代运算,推理效率更高,但由于训练过程的不稳定性,想扩展GAN是非常困难的,需要仔细调整网络架构和训练因素。不过GAN的图像生成效果也是有目共睹的,StyleGAN、Pixel2Pixel和PLUSE等模型的效果非常惊艳,而且模型规模相比扩散模型非常mini,普通设备就能实现。
总之,基于GAN框架的模型和基于Diffusion的模型各有优劣,并不能说现在扩散模型就把GAN模型打败了,PS,最近就有一篇关于扩展GAN图像生成的研究。
最后
参考文章:
The Illustrated Stable Diffusion
Scaling up GANs for Text-to-Image Synthesis
声明
本文仅作为个人学习记录。


