前言
张量(Tensor)可以看成一个多维数组(Array),张量的排列形式和数组一样
比如一个2x3张量

再比如一个2x3x2的三维张量

或者更高维度的张量,那么张量结构是如何扩展的?符合什么规律?
本文主要内容:
- 介绍了张量呈现的逻辑结构和在内存中实际存储的物理形式
- 介绍了常见深度学习框架中的张量形式的特性
- 介绍了张量中的连续存储与非连续存储
- 比较了Pytorch中部分变换张量形状的算子的差异
一、张量排列规律

从shape列表(shape就是张量的形状,比如5x5x5x3x3x3)的最右边往左遍历,最开始三个阶按照“右-下-里”的顺序排列,然后打包成一个group,再将整个group按照“右-下-里”的顺序排列,满三次后再打包成一个group,如此往复循环
上述是按行优先排列,即优先排行,再排列,直观上看就是先右再下
比如c/c++底层按行优先,pytorch、tensorflow、numpy底层是c/c++,也是按行优先,常见的列优先是caffe和matlab
二、tensor在内存中的存储方式
不论张量有多高维度,甚至想象不出来的维度大小,在内存中都是按一维数组排列
直观呈现的叫逻辑结构,内存中实际存储的形式叫物理结构
排列规律可以在参考资料里查看,物理结构排列方式跟逻辑结构不断扩展维度的规律一样,逐个填充到内存。这里使用直观的例子进行解释
举例说明:
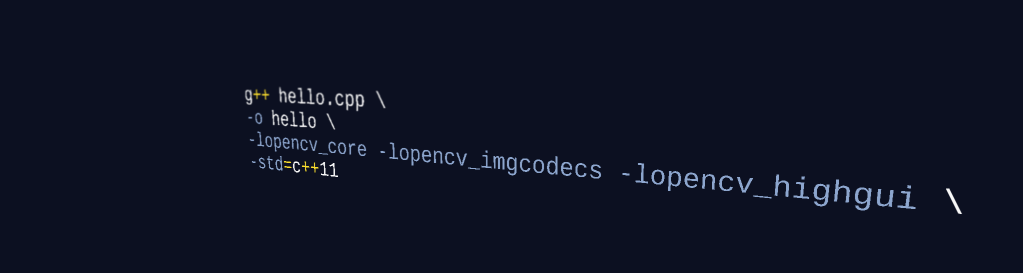
一张2x2的RGB格式的图像,
-
使用“NCHW”方式的逻辑结构如图
实际存储也是按“右-下-里”的顺序依次存到内存,如图
.png)
-
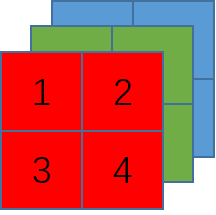
使用“NHWC”方式的逻辑结构如图
实际存储也是按“右-下-里”的顺序依次存到内存,如图
.png)
三、存储方式特性
参考资料中解释的很详细:
尽管存储的数据实际上是一样的,但是不同的顺序会导致数据的访问特性不一致,因此即使进行同样的运算,相应的计算性能也会不一样。
对于”NCHW” 而言,其同一个通道的像素值连续排布,更适合那些需要对每个通道单独做运算的操作,比如”MaxPooling”。
对于”NHWC”而言,其不同通道中的同一位置元素顺序存储,因此更适合那些需要对不同通道的同一像素做某种运算的操作,比如“Conv1x1”。
“NCHW”的计算时需要的存储更多,适合GPU运算,正好利用了GPU内存带宽较大并且并行性强的特点,其访存与计算的控制逻辑相对简单。
而”NHWC”更适合多核CPU运算,CPU的内存带宽相对较小,每个像素计算的时延较低,临时空间也很小,有时计算机采取异步的方式边读边算来减小访存时间,因此计算控制灵活且复杂。
因此,深度学习以cuDNN为底层的pytoch和caffe框架默认使用了 “NCHW” 格式,而Tensorflow采用了”NHWC”,据说是由于早期主要使用CPU加速,这也解释了为何面向移动端部署的TFLite只采用了”NHWC” 格式。
四、连续存储与不连续存储
数学解释见参考资料,这里仍以例子解释
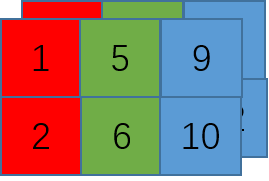
比如有一个2x3的二维张量,逻辑结构如图

物理结构如图

此时该张量称为连续张量
然后对该张量转置操作,得到的逻辑结构应该是
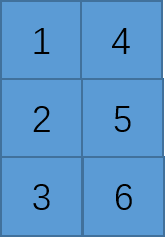
然而根据此逻辑结构得到的物理结构应该是

注意的是,此时变换操作是在原内存上进行的,物理结构没有改变,所以与上述的物理结构不同,把此时的张量称为不连续张量
对不连续存储的张量执行连续变换,也就是重新开辟内存,按逻辑结构填入对应的物理结构
连续张量中多个逻辑结构可 以对应一种物理结构,但不会出现多个物理结构对应一种逻辑结构;
不连续张量转连续张量是根据逻辑结构改变内存中数据存放顺序,改变了物理结构,所以一定存在数据拷贝。
Numpy中转连续数据使用
ascontiguousarray,Pytorch中使用contiguous
Tensorflow中,所有张量都是不可变的:永远无法更新张量的内容,只能创建新的张量,所以张量总是连续的
五、Pytorch中reshape与transpose区别
- reshape对于连续张量,共享同一内存数据,按新shape重新划分逻辑结构;对于不连续张量,按逻辑结构重新划分新的物理结构,得到连续张量,再按新shape划分新逻辑结构
- transpose会改变数据的逻辑结构,但共享物理内存
六、Pytorch中reshape与view区别
- reshape对连续张量执行
view,仅逻辑结构不同;对不连续张量先执行contiguous得到连续张量,再执行view - view只能处理连续张量,返回原张量,仅逻辑结构不同
最后
参考文章:
TensorFlow/PyTorch中张量(Tensor)的底层存储方式
声明
本文仅作为参考文章基础上的总结与个人使用记录,如有侵权,请告知删除。