前言
pytorch在学术界越来越广泛使用,Tensorflow在工业界仍然处于一哥地位,于是出现了这样的情况,很多优秀的idea和模型在学界出现,但是只有Pytorch的预训练模型,想要用到Tensorflow的框架下,模型怎么转换呢?
由于两者框架算子有一些差异,以下列举了部分算子之间的差异性。
环境:
Tensorflow 1.14.0
Pytorch1.4.0
1、转换步骤:
从Pytorch转换到Tensorflow中,基本步骤是:
1、Tensorflow重写Pytorch模型结构;
2、Pytorch保存模型参数;
3、将Pytorch的模型参数按照两框架之间对应的节点名称一一映射;
4、Tensorflow加载映射后的模型参数;
5、训练或测试。
2、Tensorflow如何重写Pytorch模型结构
这里仅讨论CNN中可能遇到的算子,包括卷积、池化、BN、激活、全连接和上下采样等。
卷积
有1D、2D、3D、空洞、反卷积…
其中主要关注点就是weights的排列方式和卷积输入数据的形状和卷积的填充补0方式
以3D卷积为例:
Pytorch中weights参数尺寸排列方式为:outchnnel * inchnnel * kernel[1] * kernel[2] * kernel[3]
Tensorflow中权值的排布方式则为:kernel[1] * kernel[2] * kernel[3] * inchnnel * outchnnel
Tensorflow反卷积中kernel[1] * kernel[2] * kernel[3] * outchnnel * inchnnel
所以转换时eights需要变换一下排列顺序
Pytorch输入数据尺寸为:batchsize * chnnel * depth * height * width
Tensorflow输入数据尺寸为:batchsize * depth * height * width * chnnel
Tensorflow的卷积算子有个data_format参数可以选择使用batchsize * depth * height * width * chnnel方式还是batchsize * chnnel * depth * height * width方式
Pytorch的卷积补0方式是两端同时补0,padding参数代表每一维两端需要补0的行数;
而在Tensorflow中,SAME方式是根据卷积计算公式,计算出需要补0的个数,优先从后方开始补,补0数目为偶数则两者相同,如果是奇数,对于height和width两个维度,就优先补右方和下方,所以这就有个大问题了,卷积的结果会对图像级的任务有较大差异,整体画面会向左上方偏移。
这里给出的解决方案是在进入卷积前手动补0,然后使用VALID方式卷积。tf.pad函数可以方便的对各个维度进行填充,不仅仅是补0,还支持复制、镜像填充。
BN
以3DBN为例:
这里要注意的是两者模型的momentum参数是相反的,就是说Tensorflow里momentum是0.9,在Pytorch里其实是1-momentum,是0.1才对,另外两者默认参数有不一样的地方,如果模型定义时没有指定,就需要注意默认参数的差异了。
Tensorflow的BN有axis参数可以指定哪一维是depth维
上采样
这里主要注意插值采样方式的差异,nearest、area方式没区别,bilinear就有区别了。
我们知道bilinear有两种模式,在Pytorch中由align_corners参数决定,具体区别请看一文看懂align_corners中的介绍,同时这个问题里讨论了Tensorflow的双线性插值方式与其他库中的差别,这里仅给出结论,Tensorflow与Pytorch在双线性插值方式上是有区别的,align_corners=False时,Tensorflow没有的图像边角没有对齐,而Pytorch对齐了。
解决方法是用TF2.x中的tf.image.resize函数,但是经过试验,还是在边缘部分还是有些许差异,另一个方法是用卷积代替双线性插值,在这篇文章里使用了反卷积实现的方式,但是有个问题还是在边缘部分,由于反卷积都是补0的,而双线性插值时边缘像素是根据输入图像的像素点决定的,而不是直接补0,所以在边缘部分还是有差异。
如果想要一样的结果,又得手动填充像素值了,以那篇文章的例子为例:
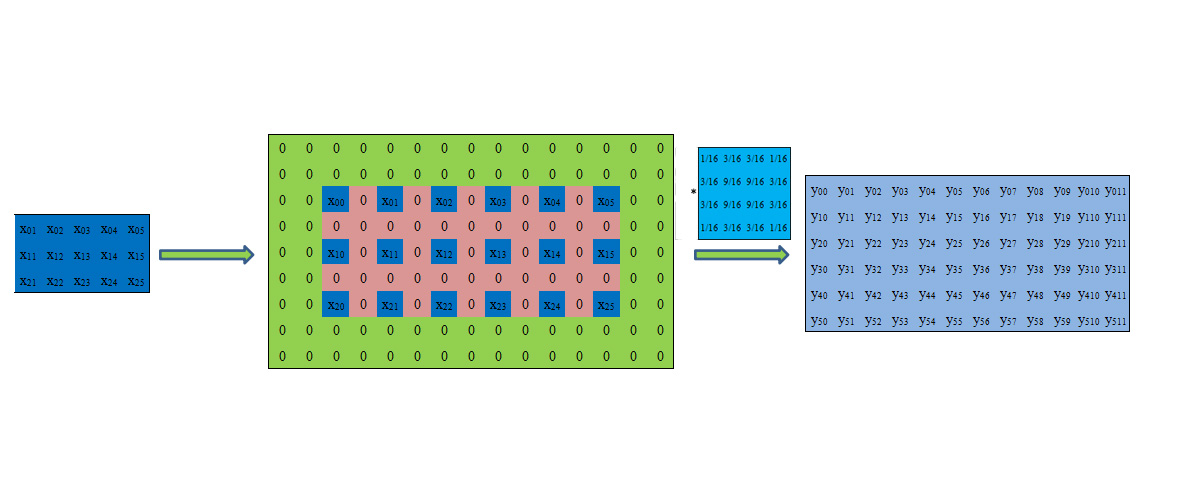
这里蓝橙相间的矩阵内部卷积结果是和bilinear方式得到的一样,但是绿色部分卷积的,也就是输出6*12尺寸下的最外一圈像素点的结果是不对的,因为绿色部分全填充了0。
边缘部分的像素值应该如下所示:
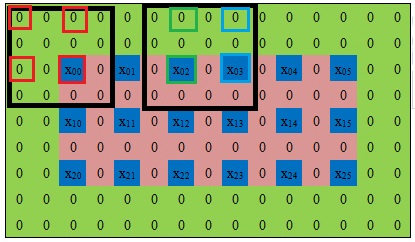
黑色方框内的相同颜色方块的值相同,只有这样卷积后的结果才和bilinear相同。Tensorflow中手动填充的步骤可以是:先使用tf.pad函数的复制填充一圈,得到边缘像素的复制值,再行列分别间隔补0;然后直接输入VALID方式的卷积算子中。
Pytorch的functional.interpolate函数有trilinear,可以直接输入5D的形状数据,而Tensorflow中的resize只能输入4D的,想要对三维数据插值需要手动分别在depth维上计算
其他算子如池化、全连接等操作影响不大,不作介绍了。
3、节点如何一一映射:
这里主要是模型节点的名称差别,模型节点名称可以使用默认的,然后映射时建立对应字典,一一对应,或者在搭建模型时就定好名称。
Tensorflow默认情况下卷积的weights名称叫kernel,Pytorch叫weight,bias相同;
BN的weight和bias分别叫gamma和beta,Pytorch下叫weight、bias。
Tesnorflow下模型结构用tf.variable_scope函数定义时,从属连接用‘/’连接,Pytorch用‘.‘。
可以直接打印出模型参数节点一一比较
#Pytorch下打印每一层的参数名和参数值
for name,param in model.named_parameters():
print(name)
#Tensorflow下
all_vars = tf.global_variables()
for v in all_vars:
print(v.name)
4、保存加载映射后的模型参数
将Pytorch的模型参数加载,得到一个模型名称-模型参数的字典,将字典映射成Tensorflow可识别的,用Tensorflow的saver保存成ckpt,下次就直接导入ckpt文件即可。
本人在保存时只能使用tf.train.Saver(new_state_dict)指定保存的节点,如果使用tf.train.Saver()就不成功
同样,加载时也指定加载的节点
最后
Pytorch与Tensorflow各有所长,但有部分不兼容的操作,在转换时需要多留意,本文只介绍了几种算子差异。Tensorflow静态图操作起来挺麻烦的,2.x中的默认动态图方便了很多。
声明
本文仅个人学习总结,如有错误,请指正。


