前言
最近在研究怎么把普通的2D视频转成3D立体视频,说白了就是从一个摄像头拍的画面里”脑补”出左右眼的视差,让你戴上3D眼镜就能看到立体效果。这个方向其实挺有意思的,不管是给老电影”翻新”成3D版本,还是给VR头显生产内容,都有实打实的应用场景。经过两个方案的模型训练与评估,目前我们有两条技术路线:一条是基于深度估计的传统流水线方案——先估计深度,计算视差,预测另一视角,再填补空洞修复扭曲;另一条是基于3D Gaussian Splatting的端到端方案,”一把梭”直接从单目视频重建3D场景。本篇先聊第一条路线:基于深度估计的方案设计,高斯泼溅方案后续再补。
正文
一、为什么要做2D转3D
你可能会问,现在3D电影不是都用双目摄像机拍的吗,为啥还要费劲从2D转?原因很简单——世界上绝大多数的视频内容都是单目拍摄的。那些经典老片、海量的网络视频、监控录像,全都是”平面”的。如果能用算法把它们转成3D,那可玩的空间就太大了:
- 老片修复与再利用:想象一下用3D的方式重新看一遍《霸王别姬》,那种沉浸感完全不一样。影视行业对经典内容的3D化改造一直有需求,但传统的人工逐帧转制成本极高,一部电影动辄几百万。
- VR/AR内容生产:VR头显需要双目视频才能呈现立体效果,但目前VR原生内容严重不足。如果能把现有的2D视频自动转成VR可用的格式,内容生态一下子就丰富了。
- 裸眼3D显示:现在越来越多的裸眼3D屏幕出现在广告牌、手机上,这些设备同样需要多视角的内容源。
二、核心技术:单目深度估计
2D转3D的核心问题,其实就是一个问题:从单张图像中估计每个像素的深度。人眼之所以能看到立体,是因为左右眼之间有大约6.5cm的间距,同一个物体在两只眼睛里的成像位置会有微小的偏移(视差),大脑通过这个偏移来感知深度。所以我们要做的,就是先搞清楚画面里每个点离摄像头有多远,然后根据这个深度信息”合成”出另一只眼睛看到的画面。
单目深度估计(Monocular Depth Estimation)这几年发展得很快,从早期的传统方法到现在基于深度学习的方案,精度提升了好几个量级。目前比较主流的方案包括:
- MiDaS系列:Intel ISL出品,泛化能力很强,在各种场景下都能给出还不错的相对深度图。它的优势在于不挑数据,拿来就能用。
- Depth Anything:最近比较火的一个模型,在大规模数据上预训练,深度估计的细节保持得很好,边缘也比较锐利。
- ZoeDepth:能输出绝对深度(带真实尺度),对于需要精确视差控制的场景比较有用。
打个比方,深度估计就像是给画面里的每个像素贴一个”距离标签”,近处的物体标签值小,远处的标签值大。有了这张”距离地图”(深度图),后面的事情就好办了。
三、双目视频生成流程
拿到深度图之后,生成双目视频的流程大致是这样的:
第一步:深度图生成
对视频的每一帧运行深度估计模型,得到对应的深度图。这里有个关键问题是时间一致性——相邻帧的深度图不能跳来跳去,否则看起来会很”抖”。我的做法是对深度图做时域滤波,用前后帧的深度信息做加权平均,平滑掉那些帧间的突变。
第二步:视差计算与图像变换
根据深度图计算视差(disparity),然后对原始图像做像素级的水平位移。左眼图像就是原图,右眼图像通过将像素按视差值向左或向右偏移来生成。深度越近的物体,偏移量越大;深度越远的,偏移量越小。这个偏移量的大小直接决定了3D效果的”强烈程度”。
第三步:空洞填充
像素偏移之后,必然会出现一些”空洞”——原来被前景物体遮挡的区域,在另一个视角下露出来了,但我们没有这部分的真实像素信息。这时候需要用图像修复(Inpainting)的方法把这些空洞填上。简单的做法是用周围像素插值,效果好一点的可以用深度学习的修复模型。
第四步:输出格式封装
最终把左右眼的视频流封装成标准的3D格式。常见的有:
- 左右格式(Side-by-Side):左右眼画面并排放在一帧里,大多数3D电视和VR播放器都支持。
- 红蓝格式(Anaglyph):用红蓝滤色来区分左右眼,戴红蓝眼镜就能看,虽然色彩会有损失,但胜在方便预览和演示。
在我的项目里,同时支持了这两种输出模式。红蓝模式主要用来快速验证效果,正式输出还是用左右格式。
 |
|---|
| 2D原始输入 |
 |
|---|
| 3D红蓝输出效果 |
四、效果展示与挑战
从实际效果来看,对于大多数自然场景的视频,转换出来的3D效果还是挺像那么回事的。尤其是前景和背景层次分明的画面,立体感很强。但也有一些场景比较棘手:
- 透明/反光物体:玻璃、水面这类东西,深度估计模型经常”犯迷糊”,因为它们的视觉特征跟实际深度关系不大。
- 重复纹理区域:比如一面砖墙、一片草地,模型很难判断哪里近哪里远。
- 快速运动场景:运动模糊会干扰深度估计,而且帧间一致性更难保证。
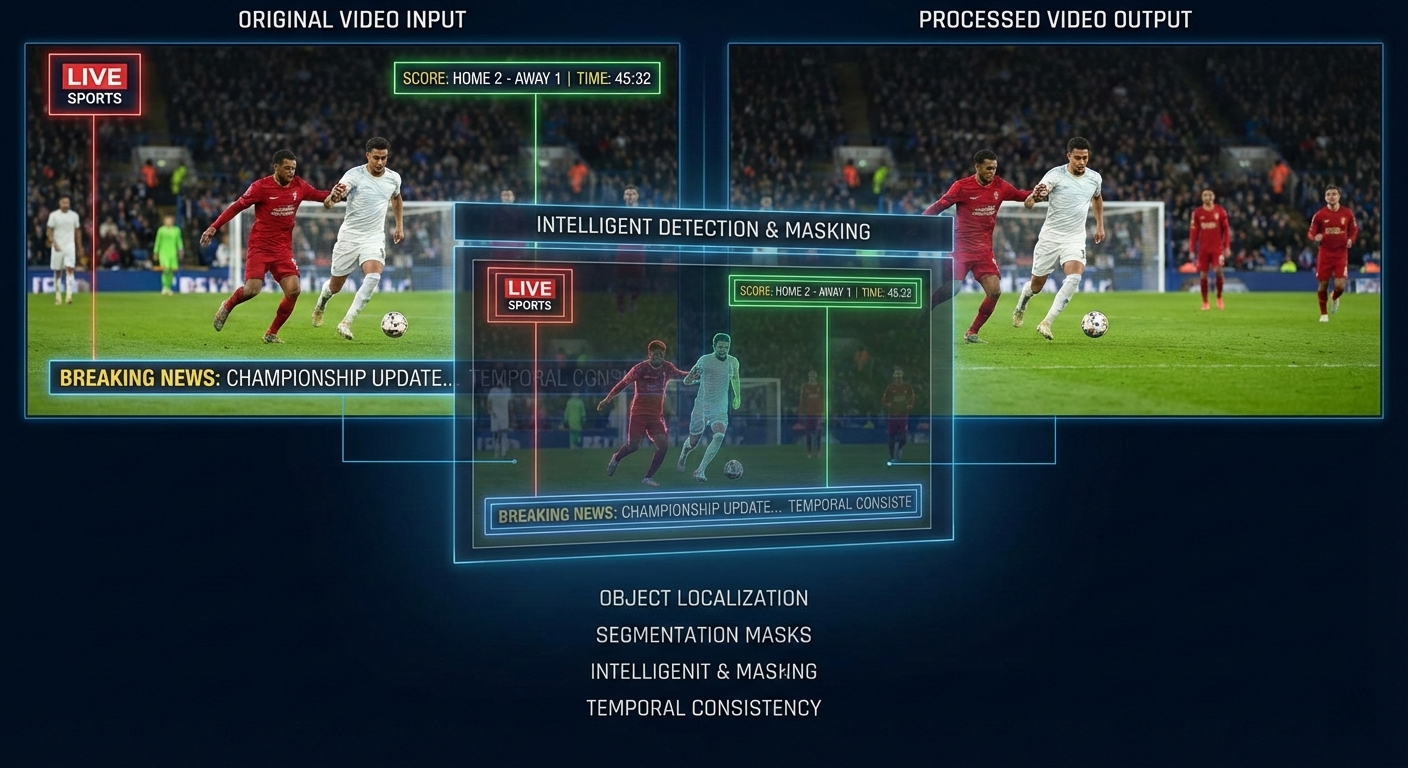
- 文字区域的特殊处理:视频里经常有字幕、台标这些叠加的文字元素。这些文字在画面中是”贴”在最前面的,如果深度估计把它们当成场景的一部分来处理,生成的3D效果会很奇怪——字幕可能会”陷”到画面里去。我的做法是先用OCR或者文字检测模型把这些区域识别出来,单独处理它们的深度值,确保文字始终在最前面的深度层。
总的来说,基于深度估计的方案流程清晰、可控性强,每个环节都可以单独调优,适合对质量有精细要求的场景。但它也有明显的局限——深度估计本身就是个”猜”的过程,对复杂场景的泛化能力有限,而且多阶段流水线的误差会逐级累积。
另一条路线——基于3D Gaussian Splatting的方案,思路完全不同:直接从单目视频重建出3D场景的高斯点云表示,然后从任意视角渲染出新视图,不需要显式的深度估计和视差计算。这个方案的优势是端到端、效果上限更高,但对数据质量和计算资源的要求也更高。关于高斯泼溅方案的具体设计和对比,后续再单独写一篇来聊。
最后
参考文章:
MiDaS - Towards Robust Monocular Depth Estimation
Depth Anything: Unleashing the Power of Large-Scale Unlabeled Data
Stereo Magnification: Learning View Synthesis using Multiplane Images
声明
本文仅作为个人学习记录,由AI辅助编写。